Webpack是现代JavaScript应用的静态模打包器。它能够内建一个被称为dependency graph的依赖关系图并生成一个或多个包。作为前端开发者,我们经常和它打交道,理解它如何工作可以使我们更好的处理我们的代码。今天我们通过一个简化版的模块打包器来理解一些它的底层逻辑。
模块打包器摘要步骤
官网给了我们一个简化版的模块打包器的例子,大体上分为三个步骤:
- 查找资源依赖:
通过JavaScript parsers生成的抽象语法树(AST- abstract syntax tree),来读取代码的内容和依赖。
这里面会做一些设置模块唯一标识(a unique Identifier)以及使用Babel将ECMAScript模块语法转化为能在当前浏览器运行的语法等操作。 - 绘制依赖关系图
取出模块的依赖包以及该依赖包所依赖的其他依赖。找出这个关系的过程称为the dependency graph。
这里会从入口文件开始,使用for循环依次遍历它的依赖,直到为空,找出每一个依赖的相对路径,拼接为完整路径,找出该路径下的资源,依次把他们添加到关系图当中的队列里。 - 将依赖封包
使用我们创建的依赖关系图生成可以在浏览器环境下运行的包。完整内容查看Detailed Explanation of a Simple Module Bundler,视频链接:Live Coding a Simple Module Bundler。
手写一个简单的Webpack
首先找一个地方创建项目文件夹,随便命名比如:minipack-demo
而后在文件夹内创建一个package.json文件,文件内容如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22{
"name": "minipack",
"version": "1.0.0",
"description": "",
"author": "Lorne Zhang",
"license": "MIT",
"dependencies": {
"babel-core": "^6.26.0",
"babel-preset-env": "^1.6.1",
"babel-preset-es2015": "^6.24.1",
"babel-traverse": "^6.26.0",
"babylon": "^6.18.0",
"eslint": "^4.17.0",
"eslint-config-airbnb-base": "^12.1.0",
"eslint-plugin-import": "^2.8.0"
},
"devDependencies": {
"eslint-config-prettier": "^2.9.0",
"eslint-plugin-prettier": "^2.6.0",
"prettier": "^1.10.2"
}
}
而后在控制台执行npm install安装依赖。
依赖安装完成后,我们就有了开发环境,接下来我们写一个简单的模拟程序,首先创建三个文件JS文件,名称和内容如下:
name.js1
export const name = 'world';
message.js1
2
3import {name} from './name.js';
export default `hello ${name}!`;
entry.js1
2
3import message from './message.js';
console.log(message);
如上这三个文件是互相依赖的关系。
而后,我们创建文件bundle.js,用于写我们的打包代码:整个项目的目录结构看起来是这样的: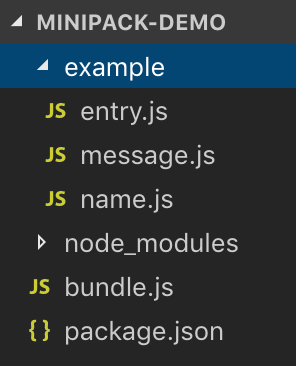
到此我们正式写我们的核心逻辑–打包器代码:
bundle.js
1 | /** |
不再多说,每一步注解已非常详细。在控制台执行:1
$ node bundle.js
生成如下结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53(function(modules) {
function require(id) {
const [fn, mapping] = modules[id];
function localRequire(relationPath) {
return require(mapping[relationPath]);
}
const module = { exports: {} };
fn(localRequire,module,module.exports);
return module.exports;
}
require(0);
})({0: [
function (require, module, exports) {
"use strict";
var _message = require("./message.js");
var _message2 = _interopRequireDefault(_message);
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }
console.log(_message2.default);
},
{"./message.js":1},
],1: [
function (require, module, exports) {
"use strict";
Object.defineProperty(exports, "__esModule", {
value: true
});
var _name = require("./name.js");
exports.default = "hello " + _name.name + "!";
},
{"./name.js":2},
],2: [
function (require, module, exports) {
"use strict";
Object.defineProperty(exports, "__esModule", {
value: true
});
var name = exports.name = 'world';
},
{},
],})
如上,这是可以在浏览器下直接运行的编译后代码,将这段代码丢进浏览器的控制台可以直接查看运行结果: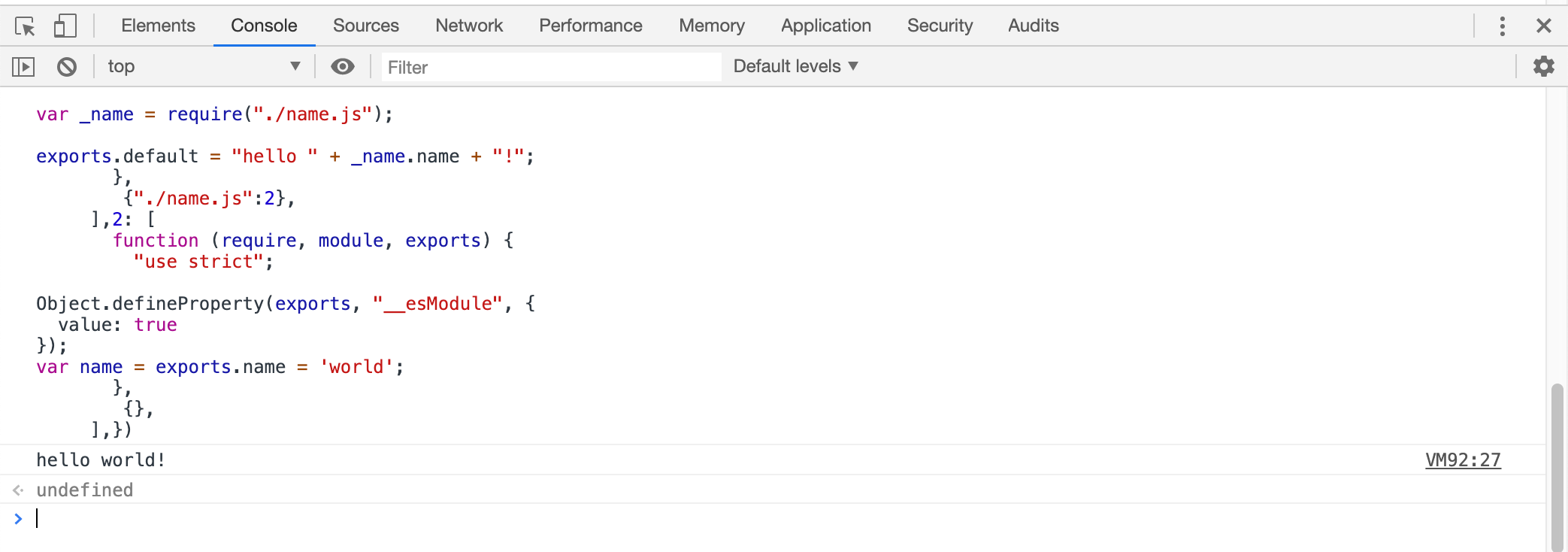
That’s OK!中文版完整程序查看minipack-demo。